1997年にチェスで、Deep Blueがカスパロフを破った。
それから20年が経った。
去年あたりから、将棋や囲碁も、人間よりプログラムの方が強いと認識されるようになった。
そして、2017年12月5日に、同じアルゴリズムで、チェス、将棋、囲碁がプレイできるものができたと。
いつものように、DeepMind社からの発表である。
すでに、学習用の大量のデータを用意しなくても、学習だけで強くなるプログラムは発表されていて、たった数日でプロに圧勝したAlphaGoよりも強い AlphaGo Zero が発表されている。
今回の発表は、チェスも、将棋も、囲碁も、それぞれのゲームのルールなどを用意するだけで、同じアルゴリズムで(たぶん同じプログラムでかつ同じハードで)ゼロから学習して強くなってしまうことに成功したようだ。
次のグラフは学習曲線を示している。(以下の論文より引用)
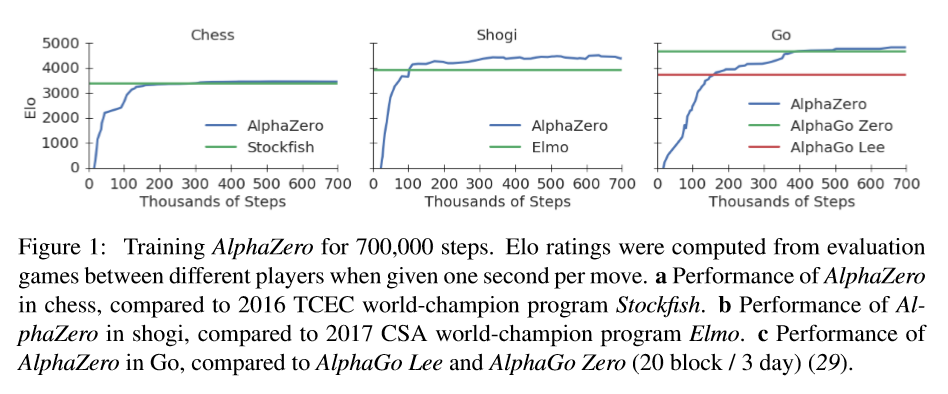
チェスや将棋は数時間の学習で世界最強になり、囲碁でも数日で十分なのである。
これについて紹介している論文がこれだ。
細かい理論や技術について書いているわけではなく、概要がざっと書いていて、最後にチェスの棋譜も載っている。
チェスの棋譜については、論文で見るより、ネットで動画になったもの、さらに解説までついたものがいっぱいあるので、そちらを見た方がよいだろう。
たとえば、YouTubeにこんなのがある。Stockfishというのは、最強のチェスプログラム(だった)。
今回の AlphaZero ではなく、AlphaGo Zero についての、楽しく分かりやすい説明がある。まあ、英語だが、このくらいは大丈夫かも。
論文の内容の解説はネットにいっぱい出ているようなので、ここでは省略する。
それより、全然違う3つのゲームが、同じアルゴリズム、同じプログラムで学習して強くなってしまったことだ。
大量の学習データがなくても、このようなゲームに関しては自己学習だけで最強になれることを示したのは大きい。
つまり、二人零和有限確定完全情報ゲームは、同じプログラムで学習だけで強くなってしまうことができるのだろうか?
ここまでできると、汎用人工知能に一歩前進は間違いないだろう。

#人気の記事
#タグ


