CNN(畳み込みニューラルネットワーク)とは
2017年 05月 13日
前回、いきなり畳み込みをChainerで使ってみた。
適当に本やネットに書かれているのを真似れば、Chainerでは非常に簡単に畳み込みができてしまう。
でも、それではちょっと不味いかと思い、遅ればせながら解説を書いておこうと思う。
畳み込みニューラルネットワークは英語では Convolutional Neural Network と言い、頭文字をとってCNNと略すことが多い。
比較的小さい正方形の配列を用意して、対象となる入力データ(画像)に適応するもので、実際には積和演算を行う。まあ、内積のことだ。
このとき、この配列をフィルタと呼ぶ。
これは、ニューラルネット以前から使われていた方法で、画像処理では昔から特徴抽出のために行われていた古典的な技術だ。
フィルタの使い方がディープラーニングになって、かなり賢くなったというか、自動化された。
昔は、人間が抽出したい特徴に合わせて、フィルタを用意し、フィルタを通した結果から、画像のどのあたりに特徴的なパターンがあるかを判別していた。
ディープラーニングでは、フィルタ、つまり配列の要素の値自体を学習により設定し、どんどん良い結果がでるようにコントロールする。
まあ、それだけなんだが、これではわかりにくいので、もうちょっと書こう。
ネット上に大量の説明が存在するので、細かい説明はここでは書かない。
しかし、ネット上の説明の多くは、1チャンネルの画像(白黒画像)の場合の例がやたらに多く、カラー画像、さらにはネットワークが多層になっていくと、チャネル数も増やしていくことが多いのだが、そのときのフィルタのサイズと、入力データのサイズ、出力データのサイズの関係があまり書かれていない。
しっかり勉強したい場合は、CS231n: Convolutional Neural Networks for Visual Recognition
Spring 2017 が良いと思う。スタンフォード大学の授業で、当然全部英語だ。
もうちょっと簡易に勉強できるものとして、Deep Learning for Computer Vision – Introduction to Convolution Neural Networks が見つかった。
CNNのとき、入力のチャネル数、出力のチャネル数とフィルタの関係がしっかり図解されているのがとても良い。
最後に、もっと簡単で、日本語なのだが、そのあたりが書かれているページがあったので紹介する。
Convolutional Neural Networkとは何なのか
結局、これもスターンフォードの授業を参考に書いてあるらしいので、スタンフォード大で勉強してしまうのが一番の早道のようだ。
その中で紹介されている画像を2枚紹介する。
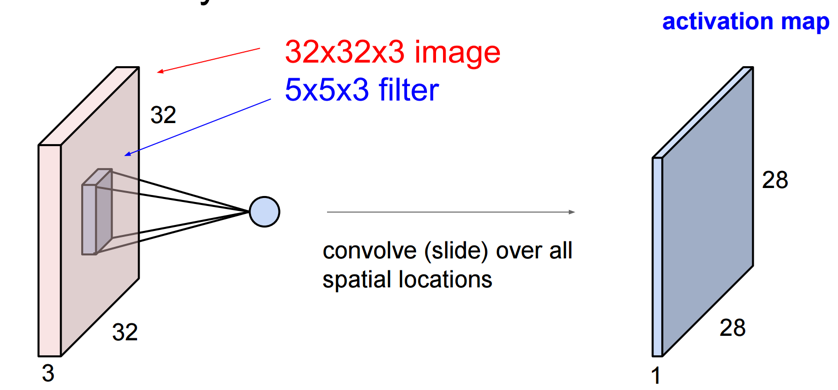
このあたりがイメージできると、計算量やメモリ使用量がわかってくる。
さて、次回はChainerに戻ろう。
適当に本やネットに書かれているのを真似れば、Chainerでは非常に簡単に畳み込みができてしまう。
でも、それではちょっと不味いかと思い、遅ればせながら解説を書いておこうと思う。
畳み込みニューラルネットワークは英語では Convolutional Neural Network と言い、頭文字をとってCNNと略すことが多い。
比較的小さい正方形の配列を用意して、対象となる入力データ(画像)に適応するもので、実際には積和演算を行う。まあ、内積のことだ。
このとき、この配列をフィルタと呼ぶ。
これは、ニューラルネット以前から使われていた方法で、画像処理では昔から特徴抽出のために行われていた古典的な技術だ。
フィルタの使い方がディープラーニングになって、かなり賢くなったというか、自動化された。
昔は、人間が抽出したい特徴に合わせて、フィルタを用意し、フィルタを通した結果から、画像のどのあたりに特徴的なパターンがあるかを判別していた。
ディープラーニングでは、フィルタ、つまり配列の要素の値自体を学習により設定し、どんどん良い結果がでるようにコントロールする。
まあ、それだけなんだが、これではわかりにくいので、もうちょっと書こう。
ネット上に大量の説明が存在するので、細かい説明はここでは書かない。
しかし、ネット上の説明の多くは、1チャンネルの画像(白黒画像)の場合の例がやたらに多く、カラー画像、さらにはネットワークが多層になっていくと、チャネル数も増やしていくことが多いのだが、そのときのフィルタのサイズと、入力データのサイズ、出力データのサイズの関係があまり書かれていない。
しっかり勉強したい場合は、CS231n: Convolutional Neural Networks for Visual Recognition
Spring 2017 が良いと思う。スタンフォード大学の授業で、当然全部英語だ。
もうちょっと簡易に勉強できるものとして、Deep Learning for Computer Vision – Introduction to Convolution Neural Networks が見つかった。
CNNのとき、入力のチャネル数、出力のチャネル数とフィルタの関係がしっかり図解されているのがとても良い。
最後に、もっと簡単で、日本語なのだが、そのあたりが書かれているページがあったので紹介する。
Convolutional Neural Networkとは何なのか
結局、これもスターンフォードの授業を参考に書いてあるらしいので、スタンフォード大で勉強してしまうのが一番の早道のようだ。
その中で紹介されている画像を2枚紹介する。
入力が3チャネル(3枚)で、サイズ5のフィルタと言った場合、フィルタのサイズは5x5x3になる。
そして、フィルタが1つにつき出力データが1チャネル(1枚)できる。
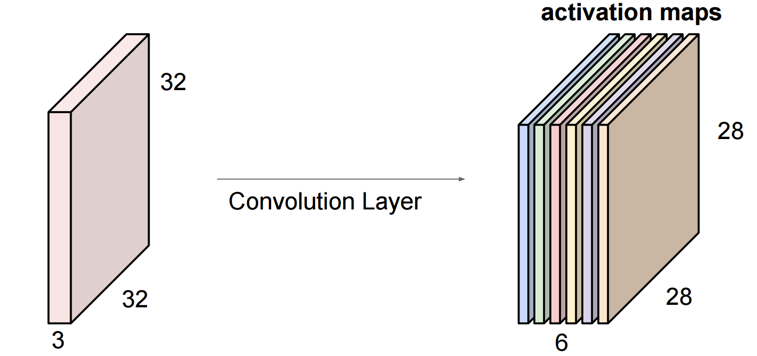
実際には、出力チャネルを複数枚にし、そのぶんだけフィルタが用意され、学習される。
上記の場合に、サイズ5のフィルタを指定したら、
サイズ x サイズ x 入力チャネル数 x 出力チャネル数
だけのフィルタ群が作られる。
そして、フィルタが1つにつき出力データが1チャネル(1枚)できる。
実際には、出力チャネルを複数枚にし、そのぶんだけフィルタが用意され、学習される。
上記の場合に、サイズ5のフィルタを指定したら、
サイズ x サイズ x 入力チャネル数 x 出力チャネル数
だけのフィルタ群が作られる。
このあたりがイメージできると、計算量やメモリ使用量がわかってくる。
さて、次回はChainerに戻ろう。

#人気の記事
#タグ


